This is a hobby project I wrote a few years ago as a fun means of getting help playing Wheel of Fortune. There weren’t any online solvers I could find at the time and even the few available now are pretty limited, so I made my own. I hope it proves a fun, interesting, or informative tool for someone! Read on for a lot more detail about it…
Link: Puzzle Solver OnlineIntroduction
The Wheel of Fortune
When I still had television several years back, I was enjoying watching Wheel of Fortune in the evenings. Wheel of Fortune is a very entertaining game show; Pat Sajak and Vanna White must think so too since they’ve been hosting it for over 30 years! It is essentially Hangman, in which a player attempts to guess the correct letters to fill in the blanks of a word or phrase, but instead of a limited number of guesses, players compete to solve the puzzle first and thereby win the prize money they’ve earned based on spins of the eponymous game wheel.
Oddly, the show is entertaining not because it is difficult or requires a certain play strategy. Anyone can call out random letters, and there’s not a particularly strong argument for using one strategy versus another. For instance, a player could attempt to eliminate letters they don’t expect to be in the puzzle, but this won’t maximize money, which comes from calling letters that are in the puzzle. If you know a letter appears many times and will only earn a small amount this round, you could attempt to “save” calling the letter for when you might spin more money, but another player could call it first and get everything you could have earned. No, there’s really no justification for not just guessing the letters you think are in the puzzle. You may contend that choosing when to buy vowels requires a level of strategy, and I would agree to an extent, but in my opinion, what really makes a good Wheel of Fortune player is having excellent recall.
Algorithmic Recall
In Computer Science, the recall of a recognition algorithm is defined as the number of valid results it returns out of all possible valid results to a given query. For example, say you’re an avid dog lover searching Google for webpages about chihuahuas. If Google’s indexed a billion pages about chihuahuas, but a search only yeilds 100 million of them, the recall is pretty low, 10%. If Google returns all billion pages, the recall would be 100%.
In the context of Wheel of Fortune, players with good recall have the ability to look at a puzzle with many potential solutions and call to memory all the different words which could fit. When you see “WH__L” on the board, it could be “WHEEL” of course, but it could also be “WHIRL”. What about the medical term “WHEAL” used to describe a swollen spot similar to a welt? Each could be correct, but only those with good recall would be able to recognize all the possiblities when faced with “WH__L”. Many players would likely be pre-disposed to think of “WHEEL” simply because of the game’s name, whether or not it fit the puzzle. The truly incredible players can look at nearly empty puzzle boards and call possible solutions to mind!
IBM Watson
With this in mind, I return to my original argument that Wheel of Fortune is not difficult or stategy-based, unlike game shows like Jeopardy!. Jeopardy! requires extensive knowledge of obscure topics that can be recalled accurately and quickly. It is probably the hardest game show out there, and yet, years ago IBM built a program capable of winning Jeopardy!.
By comparison, Wheel of Fortune is essentially a dictionary lookup, with some constraints – anyone can play!1 So why doesn’t Wheel of Fortune have a Watson? IBM probably decided it wasn’t a challenging enough problem to solve. Admittedly, it’s not that complicated; I figured that there must be a lot of solvers out there for Wheel of Fortune. A few years ago, I couldn’t find any. It seemed strange to me that we have word search solvers, AI scrabble players, and all sorts of word-based puzzle games, but no one had created a tool tailored to solving Wheel of Fortune puzzles.2 I figured it’d be a fun project, so some time back, I wrote a basic solver for Wheel of Fortune. It’s not the most sophisticated program, but it was an interesting process, which is why I decided to write a bit about it.
Parts of a Solver
Here’s what a Wheel of Fortune solver needs:
-
An extensive lexicon for finding possible words
-
A dictionary for supplying parts-of-speech, word frequency, etc.
-
Constraints which force queries and solutions to maintain game rules
I do not believe you can write a valid solver program without each of these pieces. Inability to find common words prevents offering meaningful solutions. If the results are not weighted in some way, the solutions would usually be no better than random guessing, and if you don’t match the game rules, you may was well be writing a solver for a different game.
The Lexicon
I started by searching for a large list of all possible English-language words. It’s actually harder to find such a list than you would expect. Initially, I used the lexicon once provided freely by the Linguistics department at SIL. They have since removed their online lexicon, but I found it too small anyways.
Subsequently, I turned to the Moby Project. This online thesaurus has a massive collection of words. They even used to provide categorized lexicons, grouping words into acronyms, names, places, roots, and compound words. Today, they maintain a complete word list on their organization’s Github repo.
At the end of the day, the lexicon this solver uses has about half a million words and word forms from which to draw guesses. It’s important to note that while a few common names and places are included, there’s many proper nouns that are not in the current lexicon. To answer categories about pop culture, one might need to pull an extended lexicon from a reference site like wheeloffortuneanswers, but that is not a step I’ve taken for the current version.
Dictionary of Word Frequencies
The next challenge was finding a means of weighting the words. All search engines must have a form of ranking, otherwise the results will seldom be relevant. In Google’s case, the PageRank algorithm developed by co-founder Larry Page could be considered one of its keys to success.
Since we would be searching through lists of possible words, I decided to use word popularity as a means of ranking results. It stands to reason that more frequent words appear more often in puzzles, both statistically and practically speaking. Most text search systems use a related measure when ranking results. TF-IDF is a common information retrieval algorithm which stands for Term Frequency - Inverse Document Frequency. It essentially builds a corpus-specific measure of a word’s popularity to use in evaluating results. TF-IDF is also used in automatic summarization, wherein a computer attempts to find the most relevant portions of long texts.3 It should be noted that in both search and summarization, the goal is to find less frequent words since they may be more important (e.g. keywords) to the user’s query, but in our problem of solving puzzles based on popular words and phrases, we want the most frequent words.
It turns out, linguists have written entire books on this subject. Several experts from Lancaster University – Geoffrey Leech, Paul Rayson, Andrew Wilson – wrote a book entitled Word Frequencies in Written and Spoken English: based on the British National Corpus. Not only is the book itself a very informative and useful reference, but the companion website includes large lists of words and their frequencies organized by parts-of-speech.
In total, about 6,000 words are in the final dictionary. This may seem like a tiny corpus compared with the full lexicon, but the dictionary includes only word bases, not all the forms and variations that can be found in the lexicon, and you might be shocked at how extensive a collection of 6,000 words actually is. In 2013, Test your vocab published a study showing that an average English speaker’s vocabulary is between 20,000 and 35,000 words. While they don’t specify if this number includes different word forms, it still demonstrates that a dictionary of popular words is much smaller than a lexicon of hundreds of thousands of words.
Constraints
There’s a few specific rules that must be observed for Wheel of Fortune. If a letter has been called and is not in the puzzle, it must not be in any of the words. If a letter appears at all in the puzzle, it cannot appear anywhere else in the puzzle or it would already be visible. Tossup rounds ignore both of these rules, showing random letters at regular intervals. These all seem like common sense when watching the show, but they are important considerations when writing a solver. It is tempting to equate finding solutions with a simple search of possibilities for each word, but all the words in the puzzle affect one another.
Building the Solver
Putting the Pieces Together
I chose to write the solver in Python because of its ease in handling strings, lists, and dictionaries. First, all of the lexicons are loaded into lists of strings, separated by their categories (base words, names, places, etc.). Second, word frequencies and parts-of-speech are placed into a tuple in a dictionary indexed by the word itself.
An input query is comprised of the puzzle itself (e.g. “W_EE_ OF FO___NE”) and a list of letters not in the puzzle. The puzzle is split into its constituent words, and the list of letters not in the puzzle is expanded with all letters in the puzzle. This seems counter-intuitive; it converts the list of out-letters into a single list of called-letters. One of the previously-mentioned constraints is that a letter in any word cannot appear in another word, and using a list of called-letters enforces that.
Each word and list of called-letters is used to craft a regular expression, which conducts the actual search for matches over the entire lexicon. To reduce latency, searches are conducted in tiers by category: base words, then names, followed by places, acronyms, and finally, compound words.
Once all the possible solutions have been found for each word, the list of results is sorted by word frequency. Since the dictionary is indexed by word, finding word popularity is very fast. Due to the disparity in size between the lexicon and dictionary, I noticed that a lot of solutions didn’t get assigned weights. To alleviate this issue, I added Porter Stemming via the stemming package in Python by Matt Chaput. Stemming reduces word forms to their root, and in the case of this solver, it allows the program to find word frequencies for plural and compound variants.
Lastly, a powerset of all permutations of the possible words is made. For phrases, the total ranking is given by the sum of individual word frequencies. This list of solutions is sorted by rank and the top N are chosen. I’ve experimented with different numbers for N, but so long as the puzzle isn’t using terribly obscure words, the correct words are often in the top few if not the top pick.
The Final Solution - A Webapp
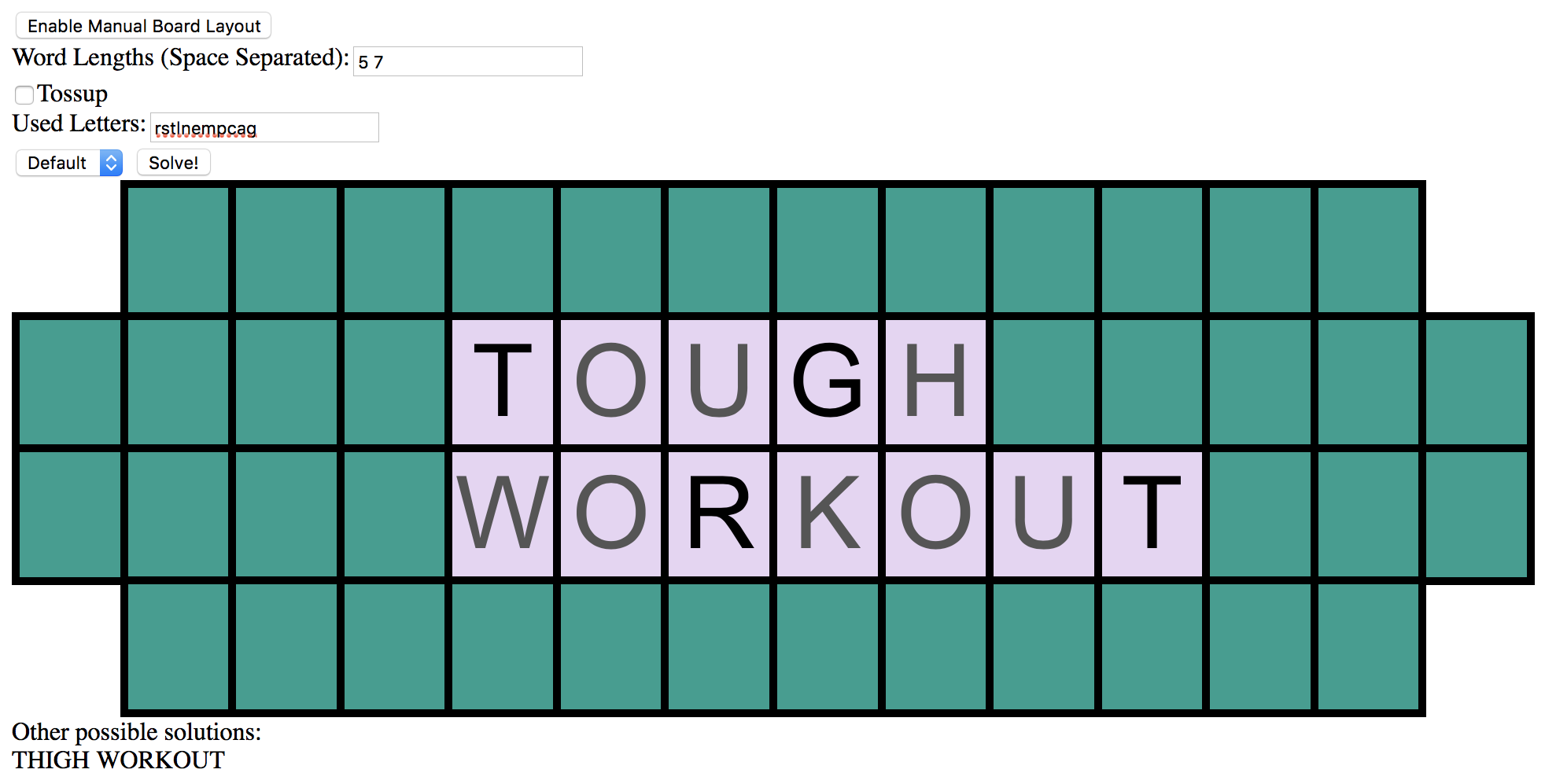
After writing a solver that can run through Python in the command line, I wanted an easy way to use it. For this purpose, I wrapped the solver in a webserver using Python’s SocketServer. The frontend for the service is a webpage styled after the Wheel of Fortune puzzle board. It’s easy to enable point-and-click puzzle layout to setup the board, or one can input the puzzle by specifying the number of letters in each word (e.g. “5 2 7” would setup a board for the “W_EE_ OF FO___NE” example I’ve been using). I didn’t really mention it before since it works much the same as solving a regular puzzle, but there is a special “Tossup” mode which makes the solver ignore the list of called or unused letters.
The webapp is available on my projects subdomain. It is linked at the top of this post, and here’s the full URL: http://projects.spolsley.com/word_solver.html
It’s imperfect, especially for puzzles about popular culture and proper names, but it seems particularly good at bonus rounds. In the bonus round, about 10 or 11 letters are eliminated from the puzzle, and they like to choose phrases which don’t have many common letters. Thus, the player must be able to think of a solution to a puzzle board that is typically almost empty. This is a difficult challenge for most people since recognition is easier than recall, and it goes back to my earlier argument that players who do the best in the game have excellent recall.
Here’s the interesting thing: while the average player must work very hard to recognize a solution out of a nearly blank board, a computer program (or player with incredible recall) will get as much information from the list of unused letters as whatever’s shown on the puzzle board. It frequently turns out that the bonus round has only one or two possible solutions in the English language after you eliminate the standard 10 or 11 letters. If you think about it, that’s almost half the alphabet being excluded; the pool of possible words practically disappears! Humans struggle to see this, but the computer does not.
In the compilation of amazing Wheel of Fortune wins linked above, the last solve was a history-making episode at the time. With her guess of “TOUGH WORKOUT”, Autumn Erhard become only the second contestant in the game show’s history to win the million dollar prize, and it was during the show’s 30th anniversary celebration too! I agree that it seems awfully coincidental that their second million dollar win happened during the 30th anniversary, but it was actually a straightforward win. As you can see, the solver would also have made Autumn’s guess; in fact, it’s one of only two possible guesses the contestant could make: tough workout or thigh workout.
Next Steps
There are definitely a few improvements I’d make if revisiting this project. I think it needs to account for parts-of-speech when selecting solutions since that would get rid of many unlikely results. The ranking could also be improved with ngram-based frequencies for words that can’t be found in the dictionary. Just as with word frequencies, ngram frequency can be counted from a corpus of text without too much difficulty. This project provides a Ruby script for doing exactly that. In addition to parts-of-speech and ngram frequency for improving general query results, I’d also like to add support for some of the Wheel of Fortune categories. Not all categories are that helpful, but from this list, you can see that categories like “Proper Names”, “Places”, and “Rhyme Time” tell you a lot about the what words fit the puzzle, and it would certainly improve the system to incorporate that information.
Of course, if you really want to write a program which can compete on Wheel of Fortune, you need to extend the solver’s capabilities. It must have a confidence value associated with each guess, something beyond the simple rank currently used. A confidence score would be necessary to choose when it’s time to attempt to solve the puzzle or keep playing. Whenever the decision is to keep playing, the system would need to choose between calling a letter or buying a vowel. Both of these pose their own unique challenges. Do you call the letter that occurs the most or the one with most confidence? Would buying a vowel now increase confidence sufficiently to solve the puzzle, or if there’s a tie between two vowels, do you pick one randomly? Along with a smattering of other decision-making elements, these are all questions which make Wheel of Fortune a “game”, and you really need a game AI in order to compete. As I mentioned at the beginning of this post, these elements of Wheel of Fortune are not that complex, any human can do it, but they are considerations which need to be made for any sort of computer system that attempts to play the game on its own.
-
In fact, it’s likely due to its simplicity that Wheel of Fortune is so universally entertaining. It has a large global audience thanks to dozens of international variants. And I would be remiss if I didn’t point out how devoted Jeopardy! fans are to their show. It can also be entertaining to test and expand your knowledge, but Jeopardy! doesn’t seem to have the same level of universal appeal. ↩
-
In the past couple of years, a few solvers have shown up online, but they remain quite limited. This one from DataGenetics cannot handle multi-word puzzles. This one on Hanging Hyena supports phrases but has a very small dictionary of possible words. Lastly, the one on dcode appears to have no means of weighting possible matches since it suggests “FOGLINE” for “FO___NE” over “FORTUNE”. ↩
-
In fact, when I was taking a class in natural language processing, I worked on a project which used TF-IDF as one feature in automated summarization of legal texts ↩